
Cada vez que alguien me pregunta cómo funcionan modelos como ChatGPT, siento que detrás de una respuesta simple hay un universo entero de procesos matemáticos, lingüísticos y computacionales. Quiero contarte, de forma amena pero rigurosa, cómo funcionan los llamados Grandes Modelos de Lenguaje (LLM), y por qué han revolucionado la forma en que conectamos con la inteligencia artificial.
¿Qué es un LLM y qué lo hace tan especial?
Los LLM son modelos de inteligencia artificial entrenados con enormes cantidades de texto para comprender y generar lenguaje natural. Modelos como GPT-4, Claude o Gemini han sido entrenados con billones de palabras, absorbiendo patrones, estilos, gramática y hechos. Pero más allá del tamaño este proceso no ocurre de forma mágica: hay un flujo estructurado de procesamiento que va desde el texto en crudo hasta su representación matemática y su posterior interpretación mediante redes neuronales.
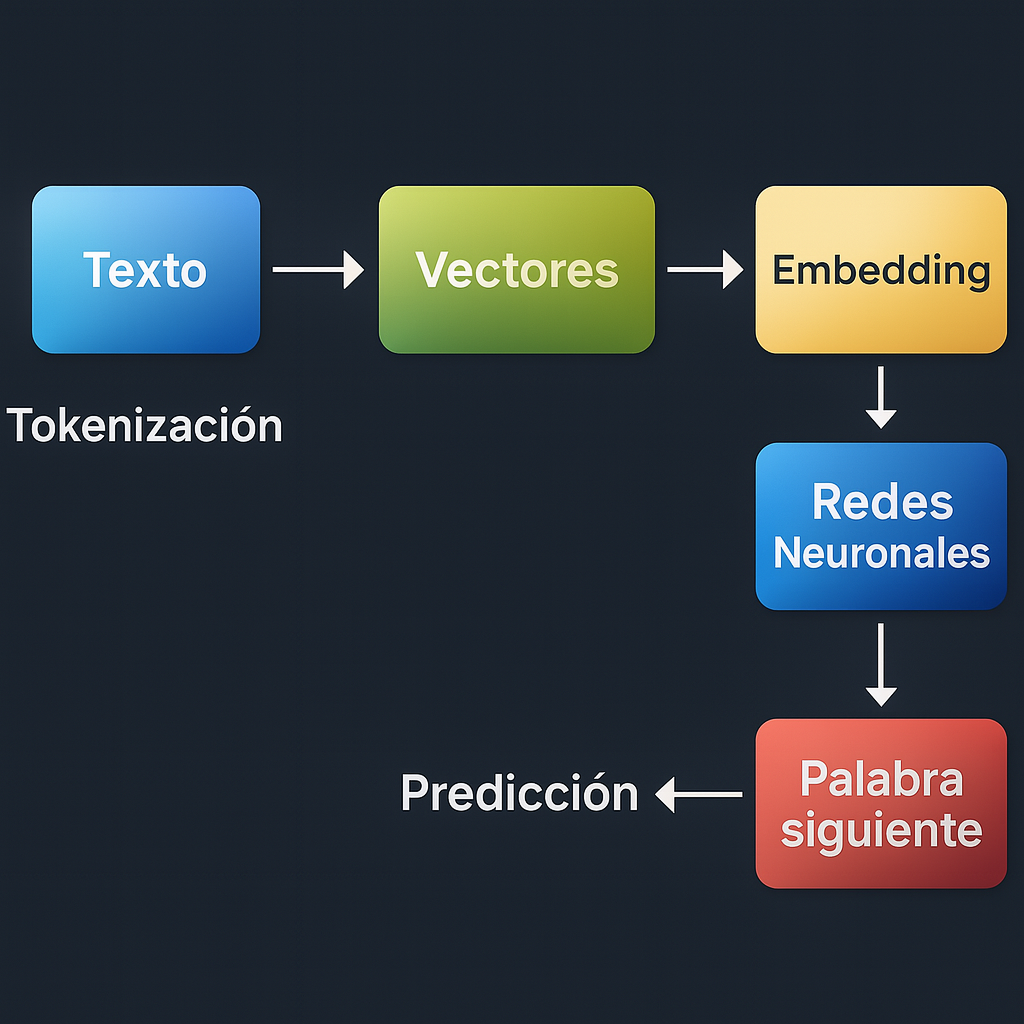
1- Tokenización: partir el lenguaje en fragmentos comprensibles
El primer paso para que una máquina entienda el lenguaje es dividir el texto en tokens, que pueden ser palabras, subpalabras o incluso sílabas. Esto permite que el modelo procese frases complejas como una secuencia ordenada de fragmentos reconocibles.
Ejemplo simple:
Texto: “Hola mundo”
Tokenización por palabras: [“Hola”, “mundo”]
Tokenización por subpalabras (BPE): [“Ho”, “la”, “mun”, “do”]
Los LLM como GPT usan tokenizadores basados en algoritmos como Byte Pair Encoding (BPE) o SentencePiece para dividir el texto en fragmentos reutilizables. Esto permite manejar vocabularios más pequeños y representar de manera eficiente palabras raras o compuestas.
2-Vectorización y Embeddings
Una vez que el texto se convierte en tokens, estos deben representarse de forma numérica para que una máquina pueda procesarlos. Esta representación se llama vectorización. Existen varias formas de hacer esto, una de ellas es One-hot encoding: Consiste en representar cada token como un vector con un único 1 en la posición correspondiente al token en el vocabulario, y 0 en las demás.
Sin embargo esto lleva a algunos problemas:
Escalabilidad: Si el vocabulario tiene 50,000 tokens, cada vector tendrá 50,000 dimensiones lo que incrementa la complejidad computacional de forma exponencial.
Semántica: Este metodo complica mucho la creacion de semantica, lo que implica crear conexiones logicas entre las palabras.
Esto lleva a la necesidad de representaciones más densas y semánticamente informativas: los embeddings.
A este punto todo se va poniendo un poco mas movido. Empecemos por las definiciones: los embeddings son vectores densos y continuos que representan tokens en un espacio de menor dimensión, donde la proximidad entre vectores refleja similitud semántica, que significa esto? pues que los vectores con mayor cercania representan palabras con un significado asociado mas profundo, gracias a esto el modelo puede entender que ‘rey’ y ‘reina’ están más cerca entre sí que ‘rey’ y ‘silla’.
Los embeddings se entrenan junto con el modelo. Inicialmente se asignan aleatoriamente y, a medida que el modelo aprende, se ajustan para que reflejen el contexto y significado de los tokens.
Cuales son las ventajas del uso de embeddings?
1-Capturan relaciones sintácticas y semánticas.
2-Permiten generalización: palabras con significados similares tienen representaciones similares.
La magia del Transformer: atención y arquitectura neuronal
El corazón de un LLM moderno es el mecanismo de atención. Para entender mejor como funciona podemos imaginarlo de la siguiente forma: cada palabra en una frase ‘mira’ a las demás para entender cuál es relevante para su contexto. Esto se logra mediante vectores llamados queries, keys y values, que permiten ponderar la influencia de cada palabra en la generación del siguiente token.
Elementos clave:
Query (Q): Vector que representa lo que buscamos.
Key (K): Vector que representa cada posible referencia.
Value (V): Vector con la información a extraer.
Imaginemos que el vector de consulta (Q) correspondiente a la palabra “su” está diciendo algo como: ‘Estoy buscando un sustantivo que describa a una persona masculina.’ Por otro lado, el vector clave (K) de la palabra “Juan” podría estar diciendo: ‘Yo soy un sustantivo que describe a una persona masculina.’
La red neuronal detecta esta coincidencia entre ambos vectores y transfiere la información contenida en el vector de “Juan” hacia el vector de his, ayudando así al modelo a entender a quién se refiere.
El mecanismo de atención multicabezal permite procesar múltiples relaciones en paralelo, con cada “cabeza” de atención enfocándose en una tarea diferente (ej., pronombres con sustantivos,resolución de homónimos).
Aca nos vamos a poner un poco mas “Matemáticos”, pero es necesario que entendemos como interactúan cada uno de los factores en juego para el calculo de la atención, dado que logra simular en gran medida como los humanos asignamos la atención a las palabras dentro de nuestro lenguaje.
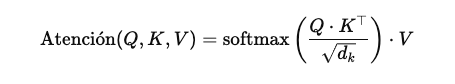
🧠 Interpretemos esto paso a paso:
-
Producto punto : mide la similitud entre cada consulta y todas las claves.
-
Escalado raiz de D: estabiliza los gradientes al evitar valores extremadamente grandes.
-
Softmax: convierte los valores en pesos de atención que suman 1 (Valores entre 0 y 1)
-
Multiplicación por : combina los valores según la importancia asignada por la atención.
Ahora es momento de pasar a la parte practica, cual es a importancia de todo esto para los grandes modelos del lenguaje, creo que podemos resumirlo estos 3 aspectos:
- Permite que el modelo entienda dependencias a largo plazo.
- Mejora la comprensión contextual.
- Sustituye estructuras secuenciales como las RNN.
El modelo no nace sabiendo. Aprende mediante un proceso iterativo donde predice palabras, compara con las correctas, calcula el error, y ajusta sus millones (o billones) de parámetros para mejorar. Este proceso, llamado backpropagation, es lo que permite que el modelo se refine con el tiempo.
A pesar de su capacidad, los LLM cometen errores: pueden inventar datos (alucinaciones), reproducir sesgos de los datos de entrenamiento, y su desarrollo implica un alto costo computacional y energético. Tener conciencia de estas limitaciones es esencial para un uso ético y efectivo.
Que podemos concluir de esta breve analisis? Bueno como científico de datos, entender cómo funciona un modelo de lenguaje me permite no solo usarlos mejor, sino también cuestionarlos, auditarlos y mejorarlos. La IA no es magia. Es ciencia, ingeniería y responsabilidad. Y cuanto más sepamos sobre ella, mejor podremos convivir con lo que viene.